AV-Speech Separation
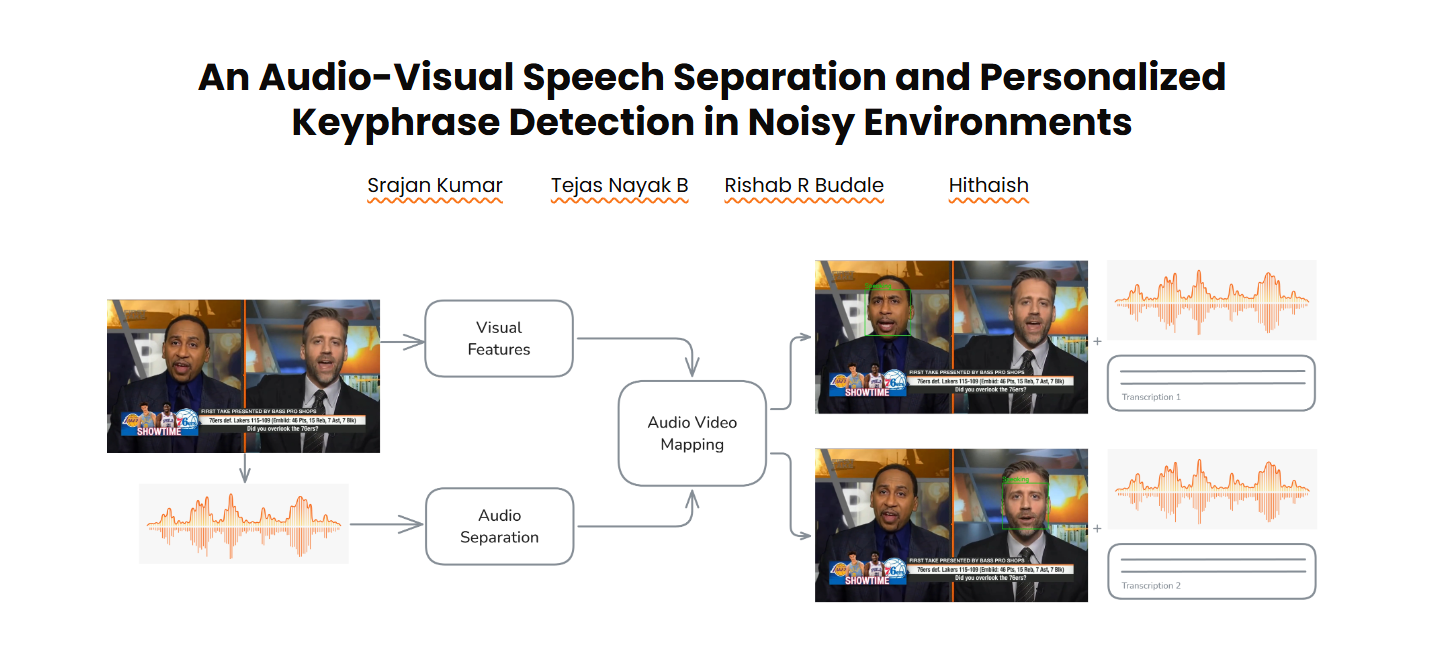
The An Audio-Visual Speech Separation and Personalized Keyphrase Detection in Noisy Environments is an advanced project inspired by the human brain's ability to focus on a single voice amid overlapping conversations, known as the cocktail party effect
Key Feature:
Speaker-Specific Audio-Visual Mapping and Captioning – The system accurately separates individual audio streams from multiple speakers in a video, synchronizes each with the corresponding lip movements, and generates enhanced, speaker-specific captions - even in overlapping or complex multi-speaker scenarios.
My teammates, Rishab R Budale, Srajan Kumar, and Hithaish, and I had the opportunity to present our paper at the 3rd Congress on Control, Robotics, and Mechatronics (CRM2025), organized by SR University, Warangal, India, on February 2, 2025. This work was built under the guidance of Dr. Priya R Kamath.